Dokuwiki hyperlinks ins markdown-Format konvertieren mit Regex
Bis jetzt hatte ich noch nicht wirklich das Bedürfnis, mich viel mit regular expressions (regex) zu beschäftigen aber endlich fand ich einen überzeugenden Grund dafür: Das Umwandeln von Dokuwiki-Syntax ins Markdown-Format, für diesen Blog. Ich arbeite hauptsächlich mit dem Texteditor Geany, dessen Suchen und Ersetzten Funktion (STRG + H) es erlaubt, Regex-Ausdrücke zu verwenden. Regex wird auch von Python unterstützt, mittels des re-Moduls.
Meine selbst gestellte Aufgabe beim konvertieren von Blogpostings:
Schnell und einfach Hyperlinks zu konvertieren:
Beispiel:
alter Link: (dokuwiki format)
[[https://geany.org|Geany text editor]]neuer Link: (markdown format)
[Geany text editor](https://geany.org)
Natürlich gibt es für Textformatkonvertierungen das Programm pandoc, ich wollte aber innerhalb meines Texteditors per Suchen und Ersetzten konvertieren können.
Heruntergebrochen in einzelne Aufgaben besteht die Konvertierung aus folgenden Operationen:
- Finde den alten Link zwischen doppelten eckigen Klammern
- Trenne den alten Link an der /pipe/ (dem senkrechten Strich: |)
- Der Teil links von der pipe (ohne die Klammern) ist der Link-Text
- Der Teil rechts von der pipe (ohne die Klammern) ist die URL
- ersetzte den alten Link mit folgendem neuen Ausdruck:
- Der Link-Text in eckigen Klammern, gefolgt von
- der URL in runden Klammern
Zuerst einmal habe ich gelernt daß Sonderzeichen welche in Regex eine besondere Bedeutung haben (z.B. Klammern) innerhalb eines Regex-Suchstrings escaped werden müssen, und zwar mit einem vorangestellten backslash (\).
Um nach einer doppelten öffenden eckigen Klammer zu suchen schreibt man deshalb anstatt [[ den korrekten Suchstring:
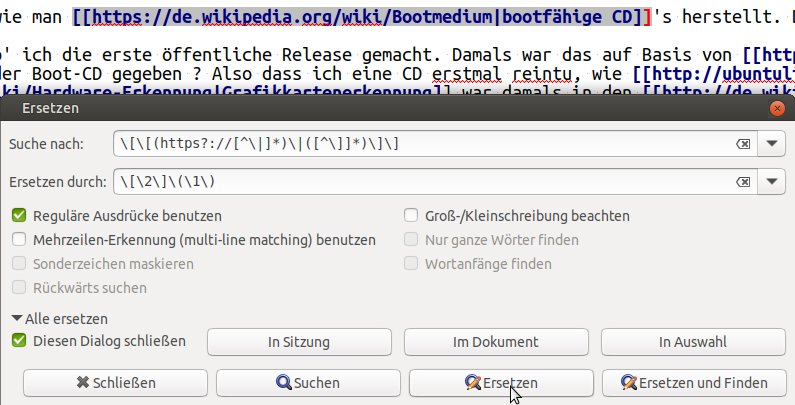
\[\[
Mit Hilfe von Geany's eingebauter Suchfunktion konnte ich dies auch gleich testen. Nicht vergessen: die Option "regulärer Ausdruck" im Geany-Suchdialog ankreuzen!
Mein nächstes Problem war die Suche nach der url. Manche Urls fingen an mit https:\\, andere ohne s: http:\\.
In Regex kann man mit einem nachgestellten Fragezeichen darstellen daß das vorangehende Zeichen Kein mal oder ein mal vorkommt.
Mein Searchstring wuchs dadurch:
\[\[https?//
Ein kleiner Test bewies daß ich sowohl http:// als auch https:// damit zuverlässig fand. Der normale Schrägstrich (Dash, /) ist seltsamerweise kein regex-Sonderzeichen und muß daher auch nicht escaped werden.
Der nächste sub-task war das finden des Pipe-Symbols. Da die urls unterschiedliche Länge hatten brauchte ich hier einen flexiblen suchstring. Laut Regex-Dokumentation würde entweder der Punkt oder ein \w funktionieren als "Joker", hat bei meinen Tests aber entweder gar nicht funktioniert oder viel zu viel gefunden.
Die Lösung war eine Exclusion: Regex durfte alle Zeichen finden beliebig oft, außer der Pipe: mit dem Effekt, dass ich damit bis zur nächsten Pipe alles fand. Ein führendes ^ -Zeichen bedeutet in Regex eine Exclusion, und da die pipe ein Regex-Sonderzeichen ist muss sie escaped werden. Die eckigen Klammern und der nachfolgende Stern bedeuten: Das, was in den Klammern steht, beliebig oft.
\[\[https?//[^\|]*
Die nachfolgende Pipe muß ebenfalls escaped werden:
\[\[https?//[^\|]*\|
Den selben Trick verwendete ich für den (beliebig langen) Link-Text: Alles außer einer schließenden eckigen Klammer beliebig oft - wobei die Klammer wiederum escaped werden muss:
\[\[https?//[^\|]*\|[^\]]*
Gefolgt von zwei schließenden Klammern (ebenfalls escaped):
\[\[https?//[^\|]*\|[^\]]*\]\]
Beim Betrachten dieses doch etwas un-intuitiven Suchstrings wurde mir klar warum ich regex in den letzten 51 Jahren nicht wirklich vermisst hatte...
Es blieb noch das Problem des Ersetzens zu lösen, mit dem replace-string.
Regex erlaubt es, beliebige Teile eines Strings in runde Klammern zu setzen und dann mit ihrem Index (mit ihrer Nummer) anzusprechen. Ich klammerte also den url-Teil (Nummer 1) und den url-Text (Nummer 2). Die eckigen Klammern und die Pipe wurden nicht geklammert.
\[\[(https?://[^\|]*)\|([^\]]*)\]\]
Der Replacement-string lautet dann: Eine (escaped) öffnende eckige Klammer, Teilstring Nummer 2, eine schließende (escaped) eckige Klammer, eine (escpaed) öffnende runde Klammer, Teilstring Nummer 1, eine schließende (escaped) runde Klammer:
\[\2\]\(\1\)
Ist doch ganz einfach :-)