How to convert dokuwiki links into markdown using regex
While I was always aware of the fact that regular expressions (regex) are a very powerful search-and-replace tool, I hardly ever used them in practice. For my humble needs, the built-in search-and-replace tool of my favorite text editor Geany is more than sufficient. From time to time, when I run into complex cases, I usually write a small Python script.
This morning, while converting old Dokuwiki-shownotes pages from my podcast into markdown format, I finally gave in: I wanted to solve a task using regular expressions.
The task was already solved inside a larger hand-written python script of mine, but I thought it would be nice to have a singular regex string that I can copy/paste into the search-replace dialog of Geany.
The task is this one:
convert a hyperlink from dokuwiki's format into markdown format.
example:
source: (dokuwiki format)
[[https://geany.org|Geany text editor]]desired result (markdown format):
[Geany text editor](https://geany.org)
And yes, I am aware of the fact that the tool pandoc can make those conversions, among many other things.
To break the task down into it's single steps:
- find source string between double square brackets
- split source string at the pipe (|)
- the part left of the pipe is the link description
- the part right of the pipe is the url
- replace the source string with:
- link description in round brackets, followed by
- url in single square brackets
Because of Geany's ability to accept regex strings inside it's search-and-replace dialog, I was able to test my regex expressions until I got the desired results. I referred to this colorful regex-tutorial site that for some reason showed up on top of my google search list: * https://www.regular-expressions.info/backref.html
I first learned that in regex, some chars like the parentheses have a special meaning and need to be escaped with an leading backslash (\).
To search for an double-opening square bracket, the searchstring is therefore not [[ but instead:
\[\[
Using Geany's search dialog (CTRL + f) for testing gave me my first little sense of achievement with regex.
My next problem was to search for the url. Some url's in my text were modern (https:\\) and some were old (http:\\). Regex provide an trailing ? operator to indicate that the previous char must occur zero or one time. I therefore modified my searchstring into:
\[\[https?//
This would find all occurrences of http:// as well as all those of https://. Strangely, the dash (/) is not a special character inside regex and does not need to be escaped.
The next sub-task was to find the pipe symbol (|). The url's inside the document have of course various length, so I needed an undefined number of any characters. According to the regex documentation I consulted, this should be possible by using either the \w or the dot but none of those worked for me satisfactory. I either got no search result at all or far too much.
The solution that worked for me was to tell regex: //take any number of chars that are NOT the pipe//. The pipe need to be escaped with an backslash, the NOT is done by an leading ^ char and for the "any number" to work the whole thing has to be inside square brackets, followed by an star. My regex searchstring grows into:
\[\[https?//[^\|]*
Now comes the pipe symbol itself. Of course, escaped:
\[\[https?//[^\|]*\|
Reflecting on those cryptic symbols, it dawned on me that why I did not really missed regex for the last 51 years in my life.
To find the link description (again, a string of various length) I used the same trick again: //any number of characters that are NOT a closing square bracket. The closing square bracket need to be escaped, and the whole term must be inside square brackets, followed by a star:
\[\[https?//[^\|]*\|[^\]]*
Finally, I search for the double square brackets of the search-string, by using escaping twice:
\[\[https?//[^\|]*\|[^\]]*\]\]
While writing this down, it all seems to be very straight forward, but in fact it took my some time, reading in Byzantine documentation websites and much trial-and-error.
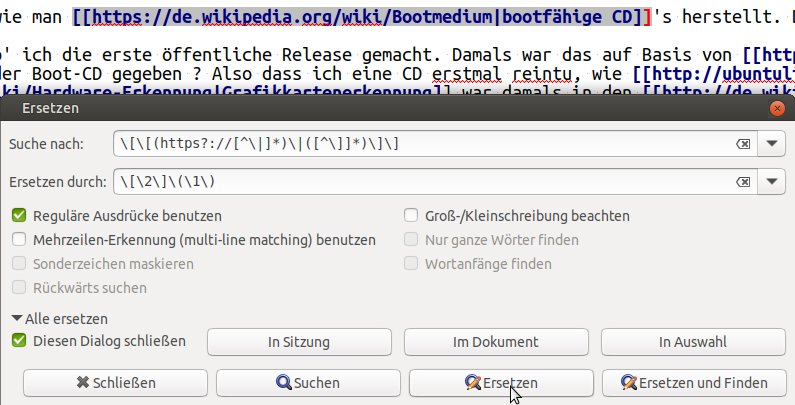
While Geany now happily found all the search strings, I needed a way to create an regex string for the replace-string.
Regex does provide a way by numbering (indexing) different parts of the search string. All I had to do was to put the different parts of the search string into round brackets:
\[\[(https?://[^\|]*)\|([^\]]*)\]\]
now the first string inside round brackets can be referred to as \1, the second string inside round brackets can be referred to as \2
My replacement string was therefore: An escaped opening sqare bracket, the second string, another (this time closed) escaped square bracket, an (again) escaped opening round brackets, the first string, and a final escaped closed round brackets. Voilà:
\[\2\]\(\1\)